EVA3D: Compositional 3D Human Generation
from 2D Image Collections
- S-Lab, Nanyang Technological University
- ✉corresponding author




























|


|


|


|


|


|


|


|


|


|


|


|


|


|


|


|


|


|


|


|


|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
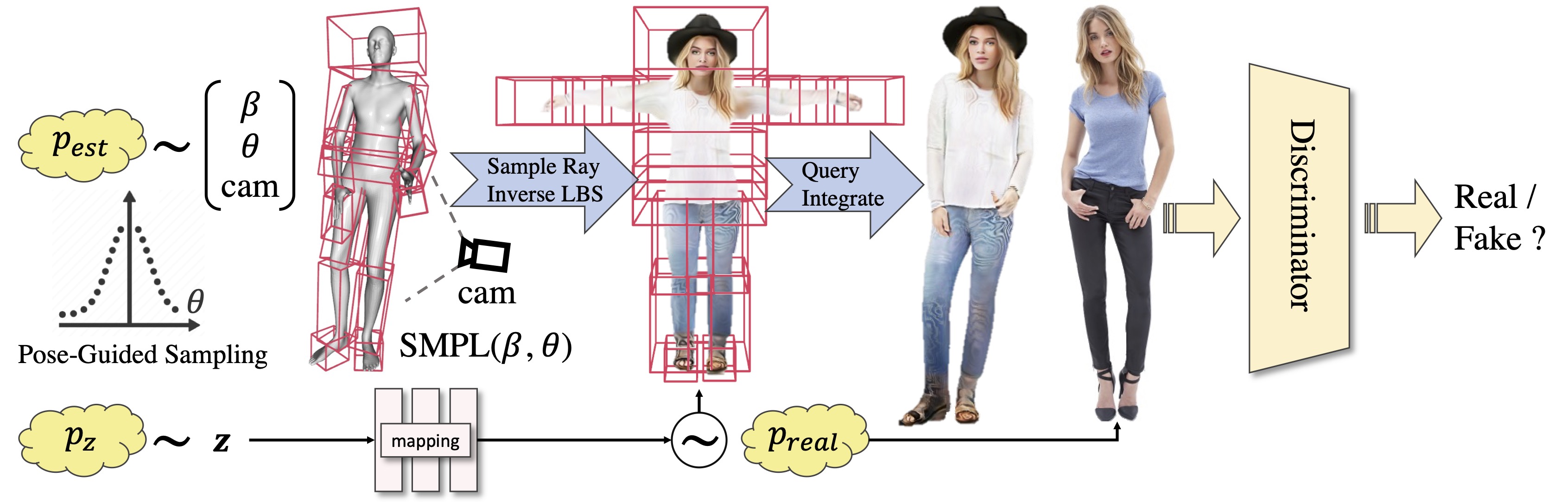 Figure 1. 3D Human GAN Framework.
Figure 1. 3D Human GAN Framework.
Our 3D human generation pipeline is shown in Figure 1. We randomly sample SMPL and camera parameters from the estimated distribution of the image collection. Together with z sampled from a normal distribution, we can sample and render a 3D human using our compositional human NeRF representation, which is shown in Figure 2. Then, the standard adversarial training in 2D space is facilitated.
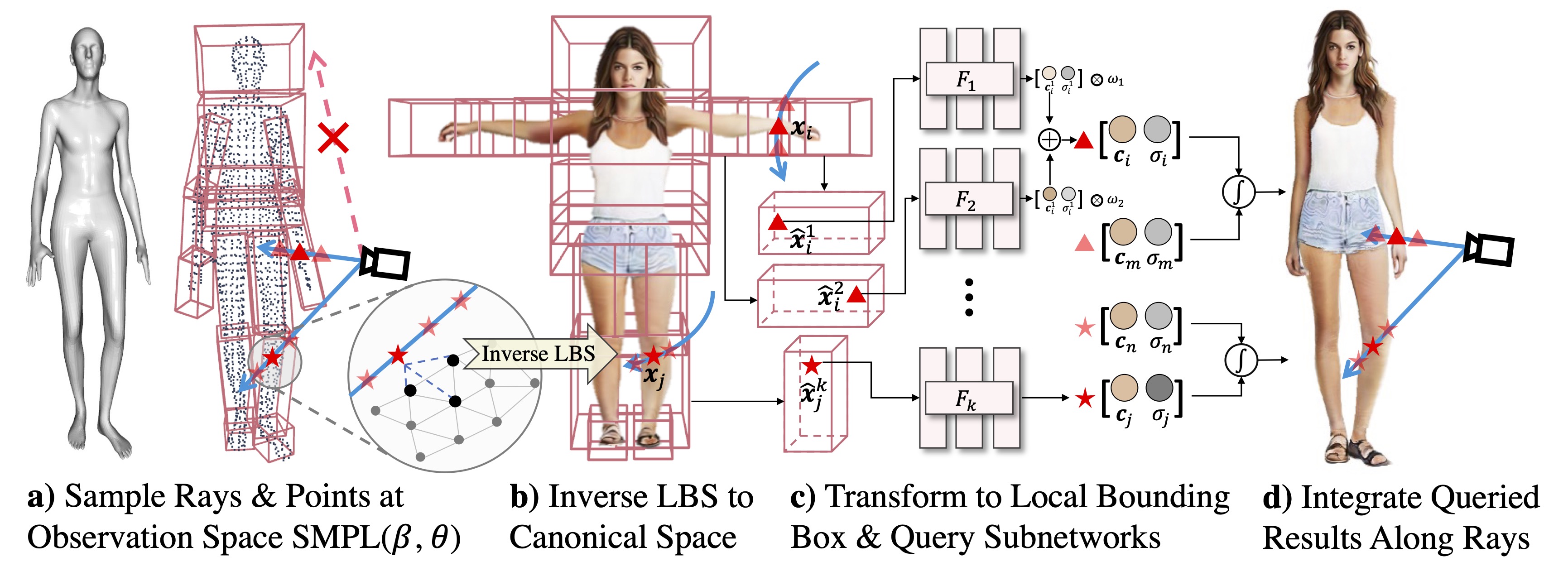 Figure 2. Compositional Human NeRF Representation.
Figure 2. Compositional Human NeRF Representation.
The core of EVA3D is the compositional human NeRF representation as shown in Figure 2. We divide the human body into local parts. Each part is represented by an individual volume. This compositional representation enables 1) inherent human priors, 2) adaptive allocation of network parameters, 3) efficient training and rendering. For more details of EVA3D, please kindly refer to the paper.
@article{EVA3D,
title={EVA3D: Compositional 3D Human Generation from 2D Image Collections},
author={Hong, Fangzhou and Chen, Zhaoxi and Lan, Yushi and Pan, Liang and Liu, Ziwei},
journal={arXiv preprint arXiv:2210.04888},
year={2022}
}
There are lots of wonderful related works that might be of interest to you.
3D Human Generation
+ AvatarCLIP generate and animate diverse 3D avatars given descriptions of body shapes, appearances and motions in a zero-shot way.
+ ENARF-GAN learns pose-controllable and geometry-aware 3D representations for articulated objects using only unlabeled single-view RGB images and a pose prior distribution for training.
+ GNARF is a 3D GAN framework that learns to generate radiance fields of human bodies or faces in a canonical pose and warp them using an explicit deformation field into a desired body pose or facial expression
+ AvatarGen learns unsupervised generation of clothed virtual humans with various appearances and animatable poses from 2D images.
+ StylePeople proposes a new type of full-body human avatars, which combines parametric mesh-based body model with a neural texture. It is capable of sampling neural textures randomly.
2D Human Generation
+ Text2Human proposes a text-driven controllable human image generation framework.
+ StyleGAN-Human scales up high-quality 2D human dataset and achieves impressive 2D human generation results.
Motion Generation
+ MotionDiffuse is the first diffusion-model-based text-driven motion generation framework with probabilistic mapping, realistic synthesis and multi-level manipulation ability.
This study is supported by NTU NAP, MOE AcRF Tier 2 (T2EP20221-0033), and under the RIE2020 Industry Alignment Fund – Industry Collaboration Projects (IAF-ICP) Funding Initiative, as well as cash and in-kind contribution from the industry partner(s).