
Fangzhou Hong 洪方舟
Ph.D., MMLab@NTU, S-Lab
- fangzhouhong820 [at] gmail.com
- Google Scholar
-
GitHub
- @hongfz16
Fangzhou Hong received his Ph.D. degree from College of Computing and Data Science, Nanyang Technological University, affiliated with MMLab@NTU and S-Lab, supervised by Prof. Ziwei Liu (2021-2025). Previously, he received B.Eng. degree in Software Engineering from Tsinghua University (2016-2020). He was fortunate to have an internship with Meta Reality Labs Research in 2023. He is the recipient of Google Ph.D. Fellowship in 2021, and China3DV Rising Star in 2025. His research interests lie in 3D computer vision and its intersection with computer graphics, with a recent focus on egocentric spatial intelligence.
One paper GeneMAN accepted to NeurIPS!
One paper CityDreamer4D accepted to TPAMI!
One paper HumanLiff accepted to IJCV!
I have successfully defended my Ph.D. Thesis (Human-Centric 3D Representation Learning)!
Invited talk at China3DV and awarded Rising Star Award (6 out of 86 global applicants)!
Five papers accepted to CVPR 2025, including 1 Oral (EgoLM) and 1 Highlight (3DTopia-XL)!
One paper GaussianAnything accepted to ICLR 2025.
One paper DiffTF++ accepted to TPAMI.
One paper HMD2 accepted to 3DV 2025.
Four papers accepted to ECCV 2024.
Invited talk at the 1st Workshop on EgoMotion.
Two papers accepted to CVPR 2024.
Two papers accepted to TPAMI (4D-DS-Net and MotionDiffuse).
Two papers accecpted to NeurIPS 2023 (one spotlight, one poster).
We are hosting OmniObject3D challenge.
Three papers accepted to ICCV 2023.
I am recognized as CVPR 2023 Outstanding Reviewer.
One paper (AvatarCLIP) accepted to SIGGRAPH 2022 (journal track).
One paper (Garment4D) accepted to NeurIPS 2021.
I am awarded Google PhD Fellowship 2021 (Machine Perception).
One paper (extended Cylinder3D) accepted by TPAMI.
Two papers (DS-Net and Cylinder3D) accepted to CVPR 2021.
Start my journey in MMLab@NTU!

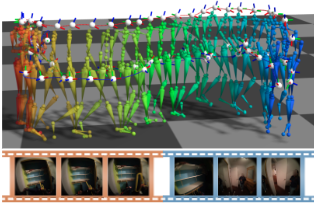
EgoLM: Multi-Modal Language Model of Egocentric Motions
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 (Oral)
EgoLM is a language model-based framework that tracks and understands egocentric motions from multi-modal inputs, i.e., egocentric videos and sparse motion sensors.

3DTopia: Large Text-to-3D Generation Model with Hybrid Diffusion Priors
arXiv Preprint, 2024


Text-to-3D Generation within 5 Minutes! A two-stage design, utilizing both 3D difffusion prior and 2D priors.
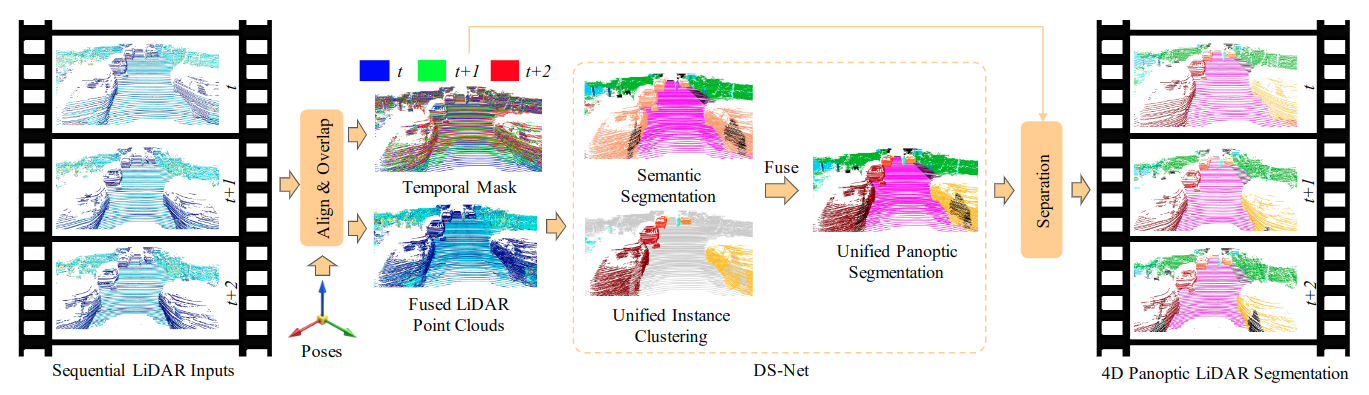
Unified 3D and 4D Panoptic Segmentation via Dynamic Shifting Networks
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023


Extension of the CVPR21 Version; Extend DS-Net to 4D panoptic LiDAR segmentation by the temporally unified instance clustering on aligned LiDAR frames.
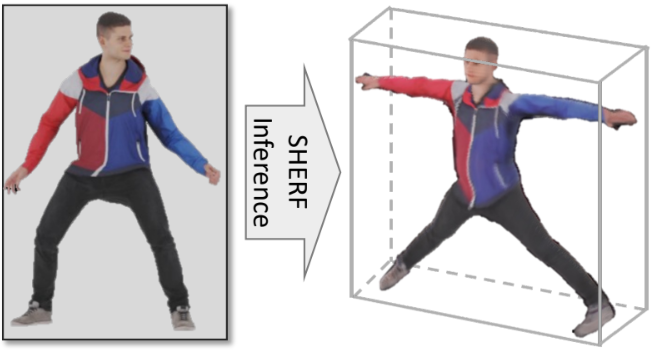
SHERF: Generalizable Human NeRF from a Single Image
International Conference on Computer Vision (ICCV), 2023


Reconstruct human NeRF from a single image in one forward pass!

EVA3D: Compositional 3D Human Generation from 2D Image Collections
International Conference on Learning Representations (ICLR), 2023 (Spotlight)


EVA3D is a high-quality unconditional 3D human generative model that only requires 2D image collections for training.
AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
ACM Transactions on Graphics (SIGGRAPH), 2022
AvatarCLIP empowers layman users to customize a 3D avatar with the desired shape and texture, and drive the avatar with the described motions using solely natural languages.
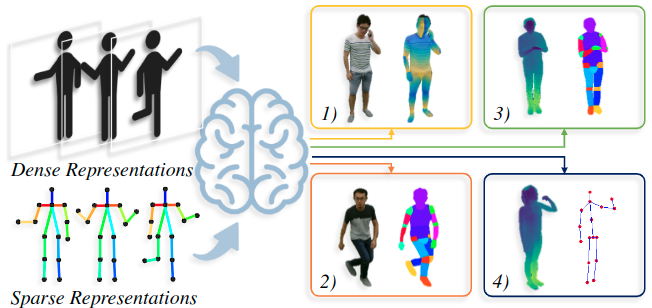
Versatile Multi-Modal Pre-Training for Human-Centric Perception
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 (Oral)


The first to leverage the multi-modal nature of human data (e.g. RGB, depth, 2D key-points) for effective human-centric representation learning.

Garment4D: Garment Reconstruction from Point Cloud Sequences
35th Conference on Neural Information Processing Systems (NeurIPS), 2021


The first attempt at separable and interpretable garment reconstruction from point cloud sequences, especially challenging loose garments.
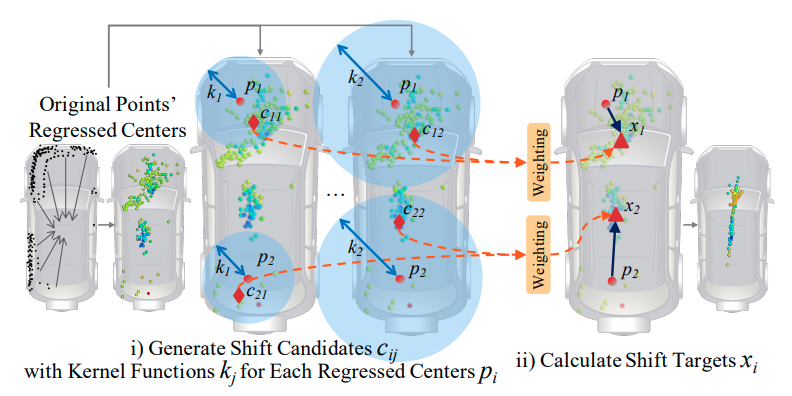
LiDAR-based Panoptic Segmentation via Dynamic Shifting Network
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Rank 1st in the public leaderboard of SemanticKITTI panoptic segmentation (2020-11-16); A learnable clustering module is designed to adapt kernel functions to complex point distributions.

GeneMAN: Generalizable Single-Image 3D Human Reconstruction from Multi-Source Human Data
The Thirty-Ninth Annual Conference on Neural Information Processing System (NeurIPS), 2025


GeneMAN is a generalizable framework for single-view-to-3D human reconstruction, built on a collection of multi-source human data.

Large Vision-Language Models: Pre-training, Prompting, and Applications
Springer Nature Switzerland
I contribute two chapters in this book: Text-Conditioned Zero-Shot 3D Avatar Creation and Animation, and Text-Driven 3D Human Motion Generation.

Compositional Generative Model of Unbounded 4D Cities
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
CityDreamer4D is a framework for unbounded 4D city generation that decouples static and dynamic scenes, achieving superior realism, multi-view consistency, and diverse styles.
Human-Centric 3D Representation Learning
Ph.D. Thesis, Nanyang Technological University, 2025
A collection of my human-related work, including HCMoCo, Garment4D, AvatarCLIP, EVA3D, EgoLM.

HumanLiff: Layer-wise 3D Human Generation with Diffusion Model
International Journal of Computer Vision (IJCV), 2025


We generate 3D digital humans using 3D diffusion model in a controllable, layer-wise way.
EgoLM: Multi-Modal Language Model of Egocentric Motions
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 (Oral)
EgoLM is a language model-based framework that tracks and understands egocentric motions from multi-modal inputs, i.e., egocentric videos and sparse motion sensors.

MEAT: Multiview Diffusion Model for Human Generation on Megapixels with Mesh Attention
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025


With mesh attention designed for efficient cross-view feature fusion, MEAT is the first human multiview diffusion model that can generate dense, view-consistent multiview images at a resolution of 1024x1024.

3DTopia-XL: Scaling High-quality 3D Asset Generation via Primitive Diffusion
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 (Highlight)


3DTopia-XL scales high-quality 3D asset generation using Diffusion Transformer (DiT) built upon an expressive and efficient 3D representation, PrimX. The denoising process takes 5 seconds to generate a 3D PBR asset from text / image input which is ready for graphics pipeline to use.

GaussianCity: Generative Gaussian Splatting for Unbounded 3D City Generation
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025


GaussianCity is a framework for efficient unbounded 3D city generation using 3D Gaussian Splatting.

EgoLife: Towards Egocentric Life Assistant
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025


We introduce EgoLife, a project to develop an egocentric life assistant that accompanies and enhances personal efficiency through AI-powered wearable glasses.

GaussianAnything: Interactive Point Cloud Latent Diffusion for 3D Generation
International Conference on Learning Representations (ICLR), 2025


GaussianAnything generates high-quality and editable surfel Gaussians through a cascaded 3D diffusion pipeline, given single-view images or texts as the conditions.

DiffTF++: 3D-aware Diffusion Transformer for Large-Vocabulary 3D Generation
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
Extension of our ICLR 2024 paper DiffTF. Joint training of diffusion model and Triplane representation increases the generation quality.
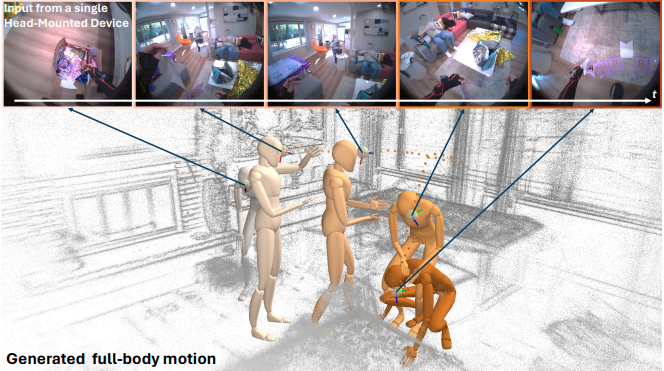
HMD2: Environment-aware Motion Generation from Single Egocentric Head-Mounted Device
International Conference on 3D Vision (3DV), 2025
We propose HMD2, the first system for the online generation of full-body self-motion using a single head-mounted device (e.g. Project Aria Glasses) equipped with an outward-facing camera in complex and diverse environments.

Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild
European Conference on Computer Vision (ECCV), 2024


A large-scale, diverse, richly annotated human motion dataset collected in the wild with multi-modal egocentric devices.

LN3Diff: Scalable Latent Neural Fields Diffusion for Speedy 3D Generation
European Conference on Computer Vision (ECCV), 2024


LN3Diff creates high-quality 3D object mesh from text within 8 V100-SECONDS.
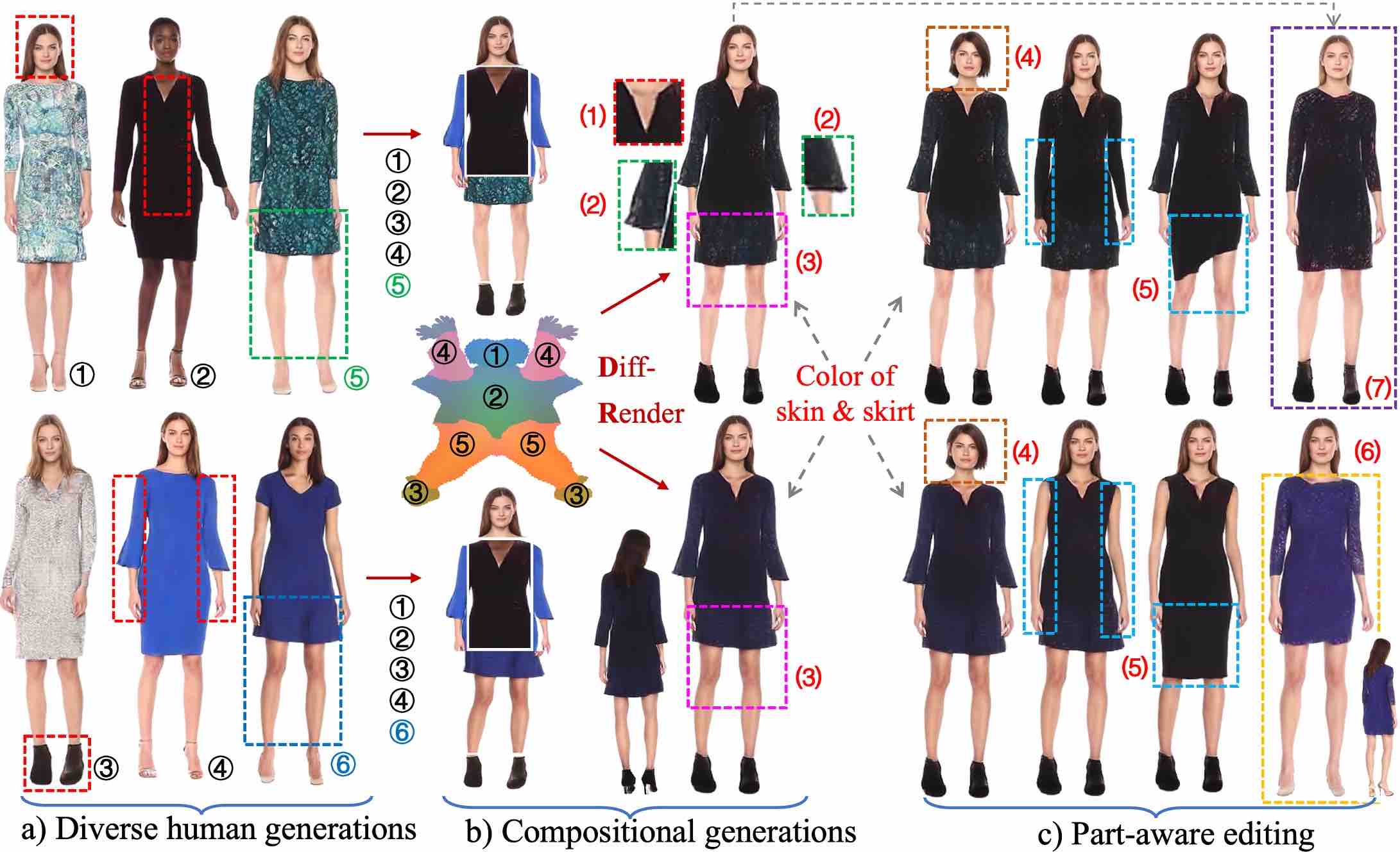
StructLDM: Structured Latent Diffusion for 3D Human Generation
European Conference on Computer Vision (ECCV), 2024


StructLDM is a diffusion-based unconditional 3D human generative model learned from 2D images.
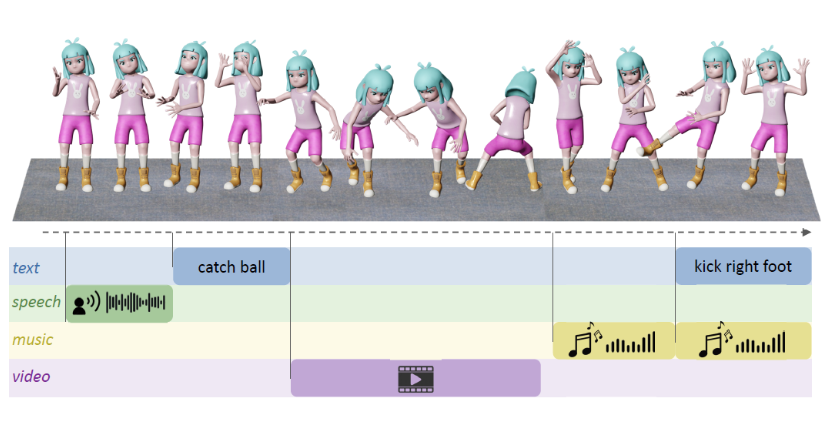
Large Motion Model for Unified Multi-Modal Motion Generation
European Conference on Computer Vision (ECCV), 2024


Large Motion Model (LMM) is a motion-centric, multi-modal framework that unifies mainstream motion generation tasks into a generalist model.

SurMo: Surface-based 4D Motion Modeling for Dynamic Human Rendering
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024


Dynamic human rendering with the joint modeling of motion dynamics and appearance.

CityDreamer: Compositional Generative Model of Unbounded 3D Cities
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024


Unbouned 3D cities generated from 2D image collections!

Large-Vocabulary 3D Diffusion Model with Transformer
International Conference on Learning Representations (ICLR), 2024


DiffTF achieves state-of-the-art large-vocabulary 3D object generation performance with 3D-aware transformers.
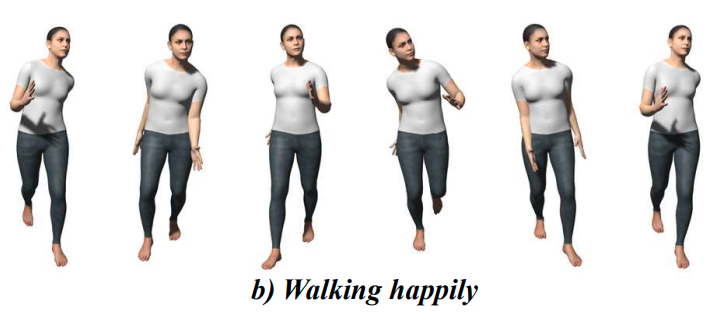
MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023


The first diffusion-model-based text-driven motion generation framework with probabilistic mapping, realistic synthesis and multi-level manipulation ability.
Unified 3D and 4D Panoptic Segmentation via Dynamic Shifting Networks
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
Extension of the CVPR21 Version; Extend DS-Net to 4D panoptic LiDAR segmentation by the temporally unified instance clustering on aligned LiDAR frames.

PrimDiffusion: Volumetric Primitives Diffusion for 3D Human Generation
Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023


PrimDiffusion performs the diffusion and denoising process on a set of primitives which compactly represent 3D humans.
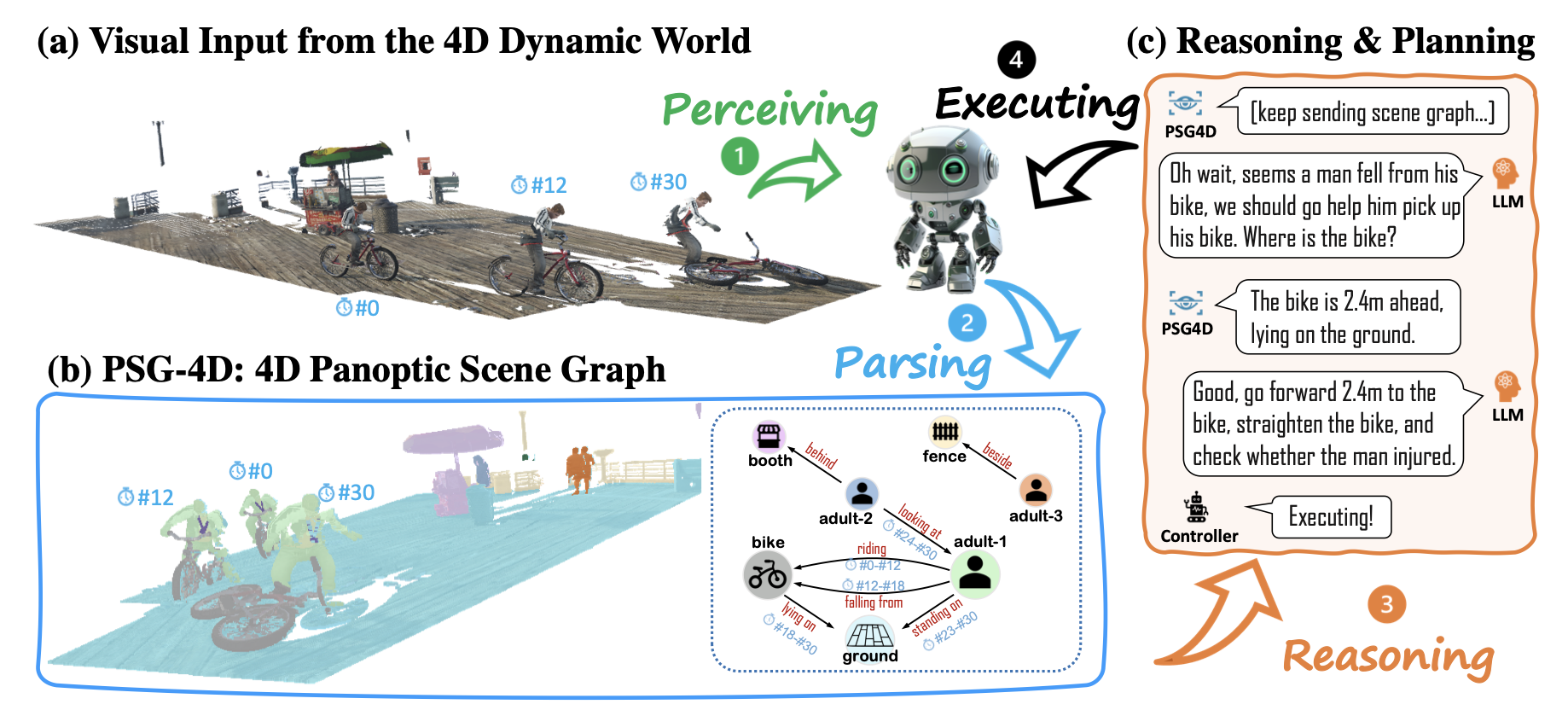
4D Panoptic Scene Graph Generation
Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023 (Spotlight)
To allow artificial intelligence to develop a comprehensive understanding of a 4D world, we introduce 4D Panoptic Scene Graph (PSG-4D), a new representation that bridges the raw visual data perceived in a dynamic 4D world and high-level visual understanding.
SHERF: Generalizable Human NeRF from a Single Image
International Conference on Computer Vision (ICCV), 2023
Reconstruct human NeRF from a single image in one forward pass!

DeformToon3D: Deformable 3D Toonification from Neural Radiance Fields
International Conference on Computer Vision (ICCV), 2023


We learn a style field that deforms real 3D faces to styleized 3D faces.

ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model
International Conference on Computer Vision (ICCV), 2023


ReMoDiffuse is a diffusion-model-based motion generation framework that integrates a retrieval mechanism to refine the denoising process, which enhances the generalizability and diversity.
EVA3D: Compositional 3D Human Generation from 2D Image Collections
International Conference on Learning Representations (ICLR), 2023 (Spotlight)
EVA3D is a high-quality unconditional 3D human generative model that only requires 2D image collections for training.
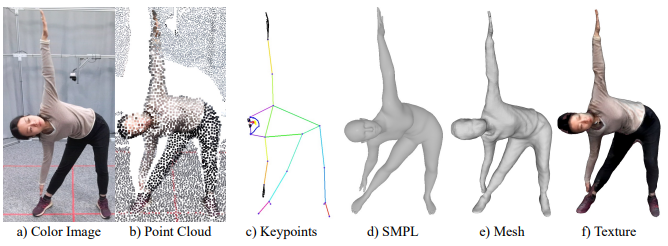
HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling
European Conference on Computer Vision (ECCV), 2022 (Oral)


A large-scale multi-modal (color images, point clouds, keypoints, SMPL parameters, and textured meshes) 4D human dataset with 1000 human subjects, 400k sequences and 60M frames.
AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
ACM Transactions on Graphics (SIGGRAPH), 2022
AvatarCLIP empowers layman users to customize a 3D avatar with the desired shape and texture, and drive the avatar with the described motions using solely natural languages.
Versatile Multi-Modal Pre-Training for Human-Centric Perception
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 (Oral)
The first to leverage the multi-modal nature of human data (e.g. RGB, depth, 2D key-points) for effective human-centric representation learning.
Garment4D: Garment Reconstruction from Point Cloud Sequences
35th Conference on Neural Information Processing Systems (NeurIPS), 2021
The first attempt at separable and interpretable garment reconstruction from point cloud sequences, especially challenging loose garments.
LiDAR-based Panoptic Segmentation via Dynamic Shifting Network
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Rank 1st in the public leaderboard of SemanticKITTI panoptic segmentation (2020-11-16); A learnable clustering module is designed to adapt kernel functions to complex point distributions.
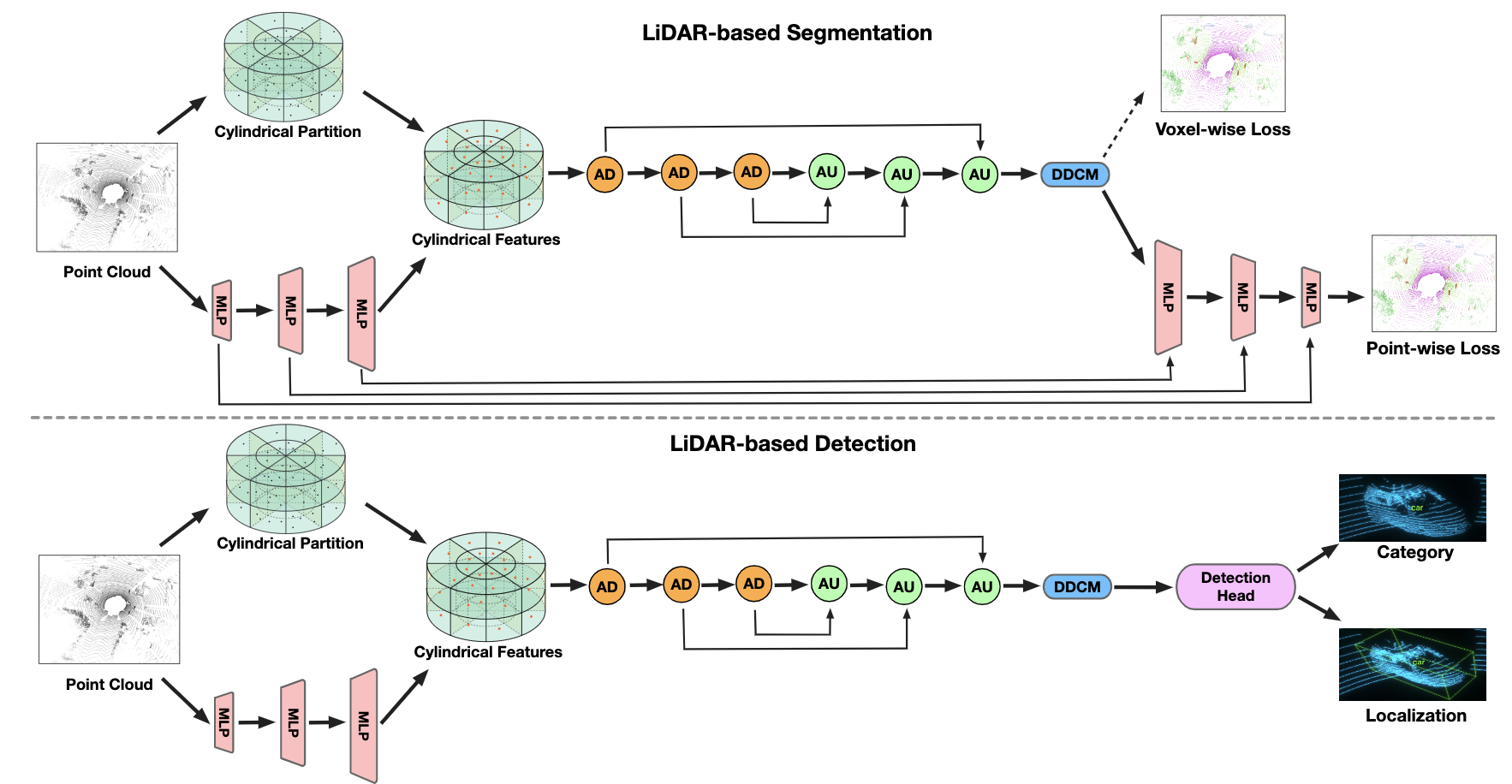
Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR-based Perception
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021
Journal Extension of the CVPR21 version; Extend the cylindrical convolution to more general LiDAR-based perception tasks.
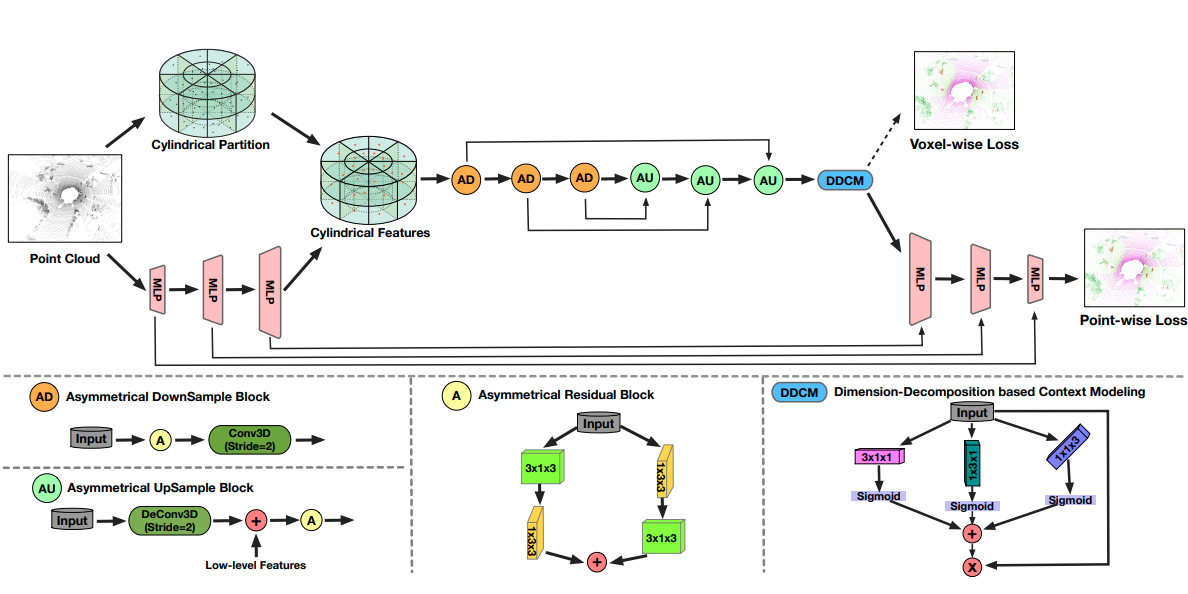
Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR Segmentation
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 (Oral)


Rank 1st in the public leaderboard of SemanticKITTI semantic segmentation (2020-11-16); Cylindrical 3D convolution is designed to explore the 3D geometric pattern of LiDAR point clouds.

LRC-Net: Learning Discriminative Features on Point Clouds by Encoding Local Region Contexts
Computer Aided Geometric Design, 2020, 79: 101859. (SCI, 2017 Impact factor: 1.421, CCF B)
To learn discriminative features on point clouds by encoding the fine-grained contexts inside and among local regions simultaneously.

EgoTwin: Dreaming Body and View in First Person
arXiv Preprint, 2025
We propose EgoTwin, a diffusion-based framework that jointly generates egocentric video and human motion in a viewpoint consistent and causally coherent manner. Generated videos can be lifted into 3D scenes using camera poses derived from human motion via 3D Gaussian Splatting.
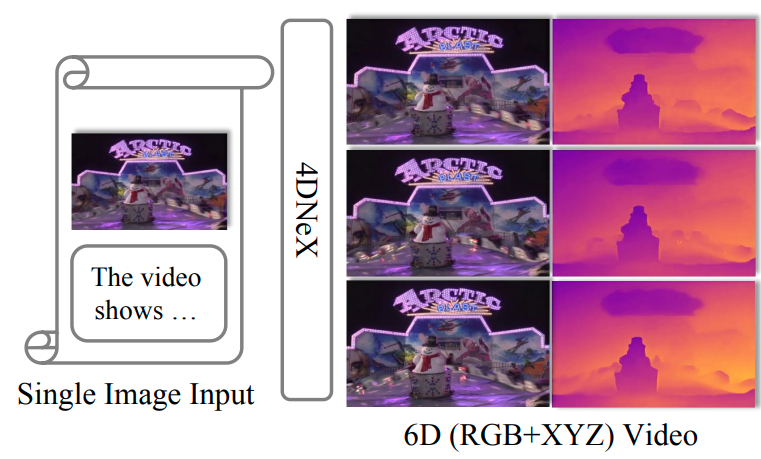
4DNeX: Feed-Forward 4D Generative Modeling Made Easy
arXiv Preprint, 2025
4DNeX is a feed-forward framework for generating 4D scene representations from a single image by fine-tuning a video diffusion model. It produces high-quality dynamic point clouds and enables downstream tasks such as novel-view video synthesis with strong generalizability.
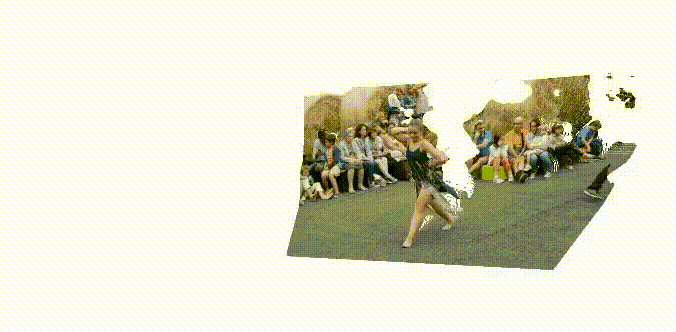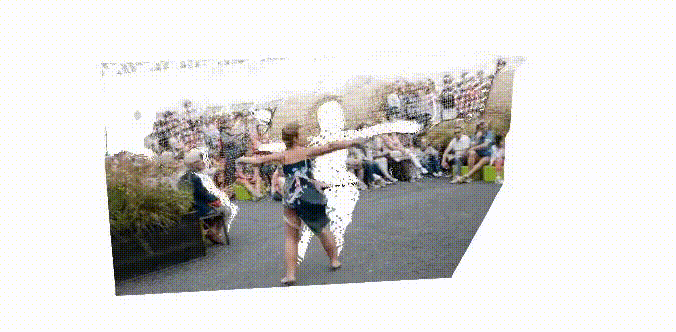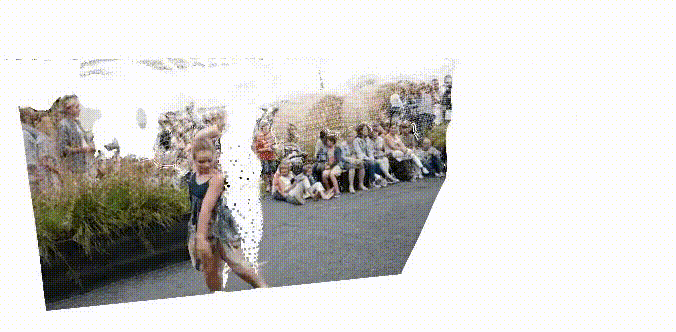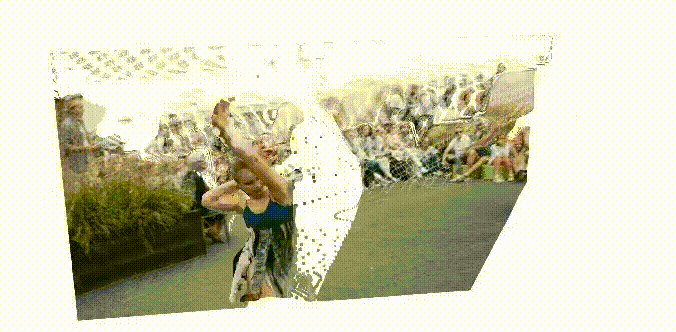
STream3R: Scalable Sequential 3D Reconstruction with Causal Transformer
arXiv Preprint, 2025
STream3R reformulates dense 3D reconstruction into a sequential registration task with causal attention.
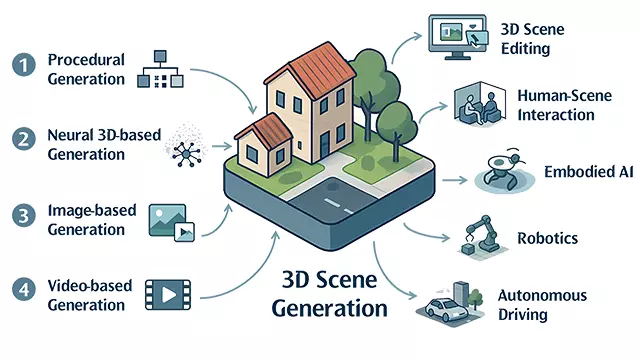
arXiv Preprint, 2025
This survey provides a systematic overview of state-of-the-art approaches, organizing them into four paradigms: procedural generation, neural 3D-based generation, image-based generation, and video-based generation.
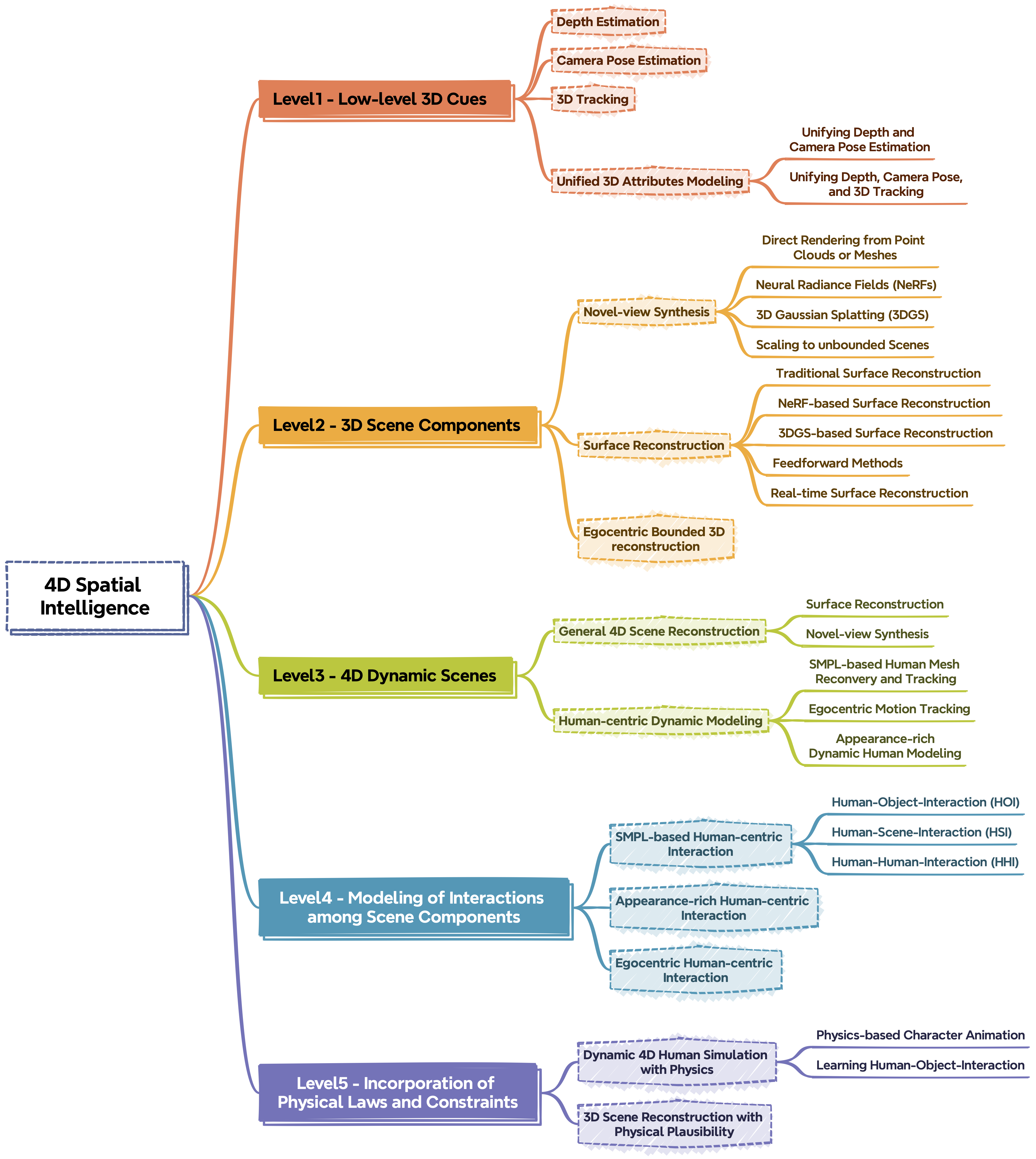
Reconstructing 4D Spatial Intelligence: A Survey
arXiv Preprint, 2025
We present a new perspective that organizes existing dynamic reconstruction methods into five progressive levels of 4D spatial intelligence.
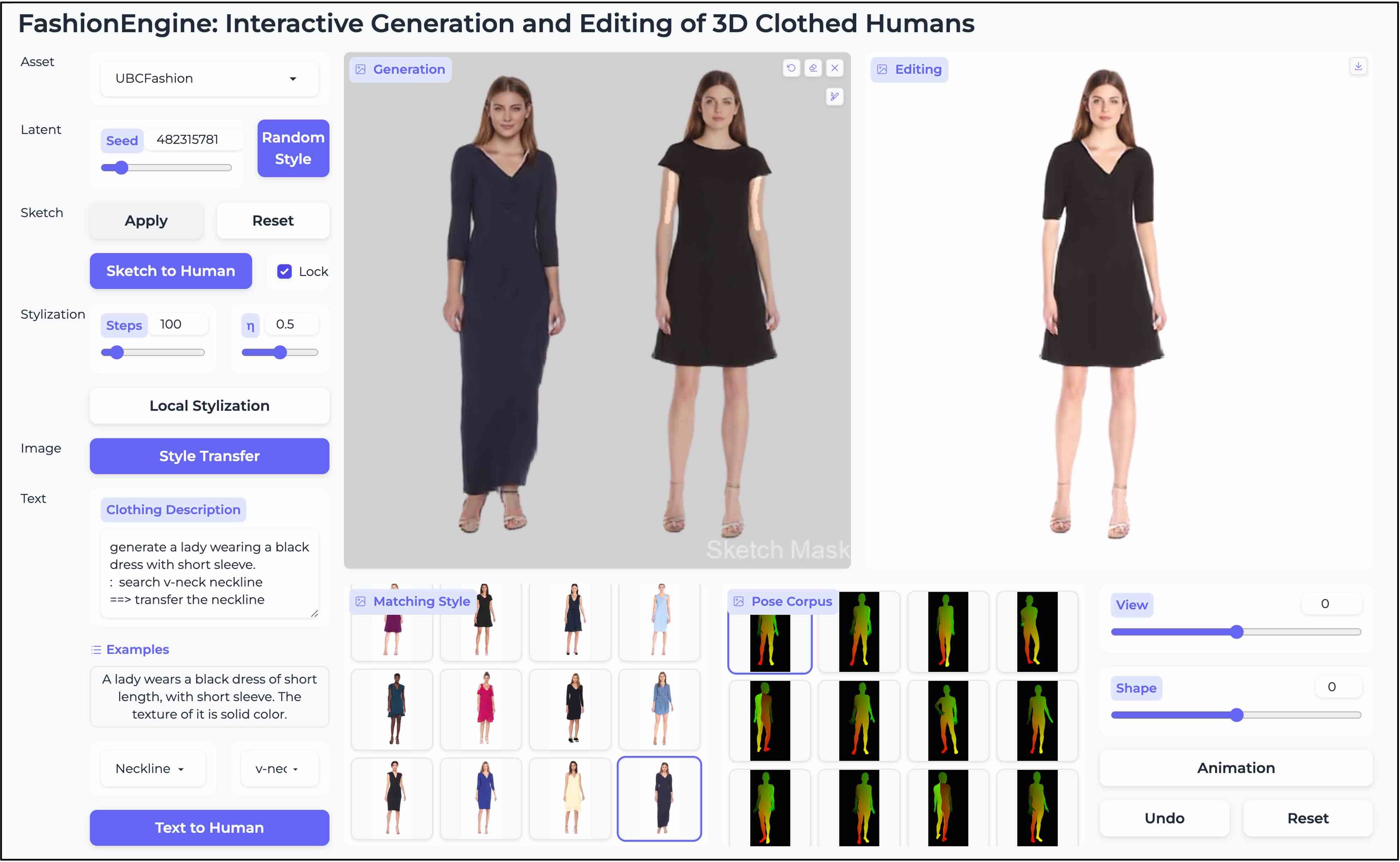
FashionEngine: Interactive Generation and Editing of 3D Clothed Humans
arXiv Preprint, 2024
FashionEngine is an interactive 3D human generation and editing system with multimodal control (e.g., texts, images, hand-drawing sketches).
3DTopia: Large Text-to-3D Generation Model with Hybrid Diffusion Priors
arXiv Preprint, 2024
Text-to-3D Generation within 5 Minutes! A two-stage design, utilizing both 3D difffusion prior and 2D priors.
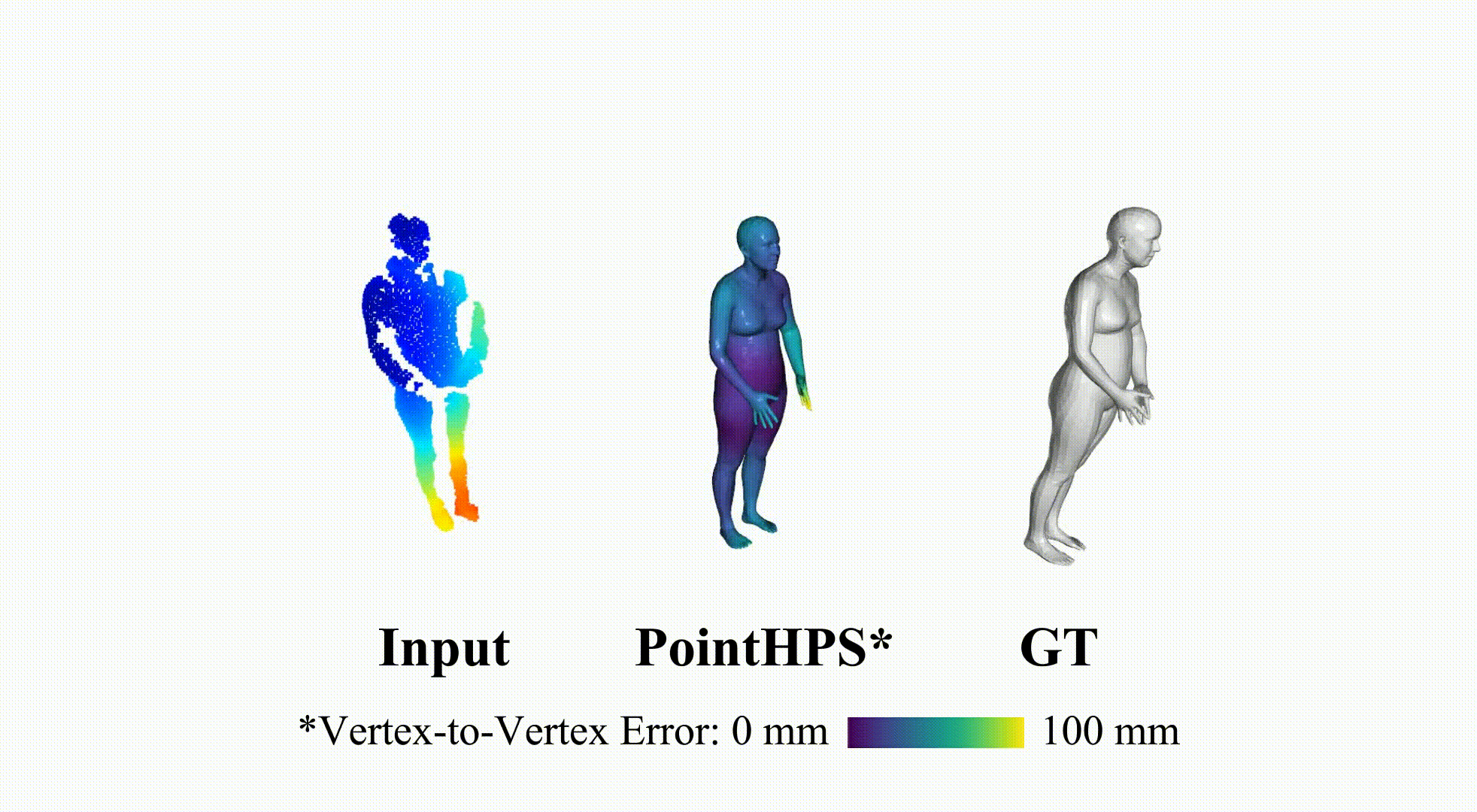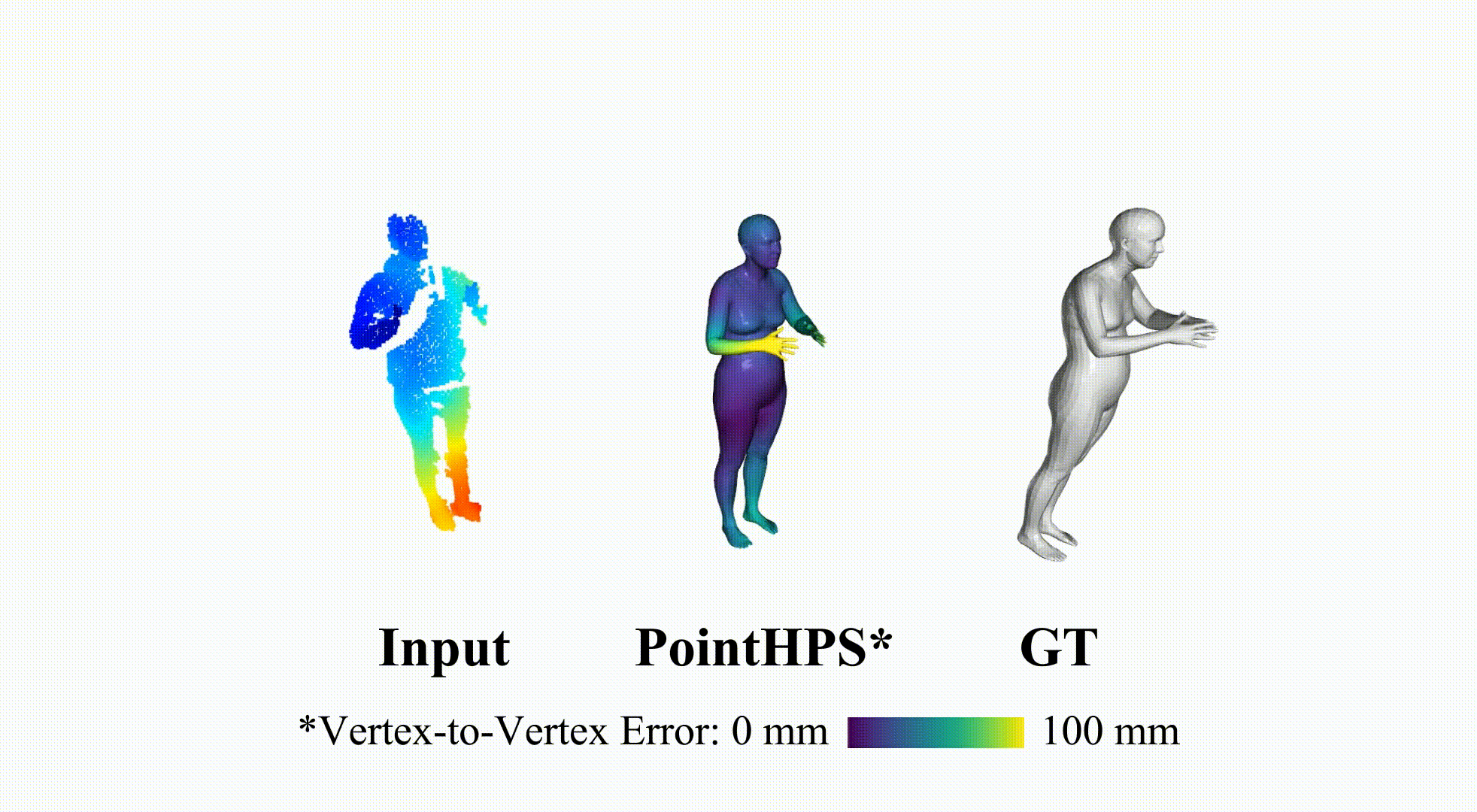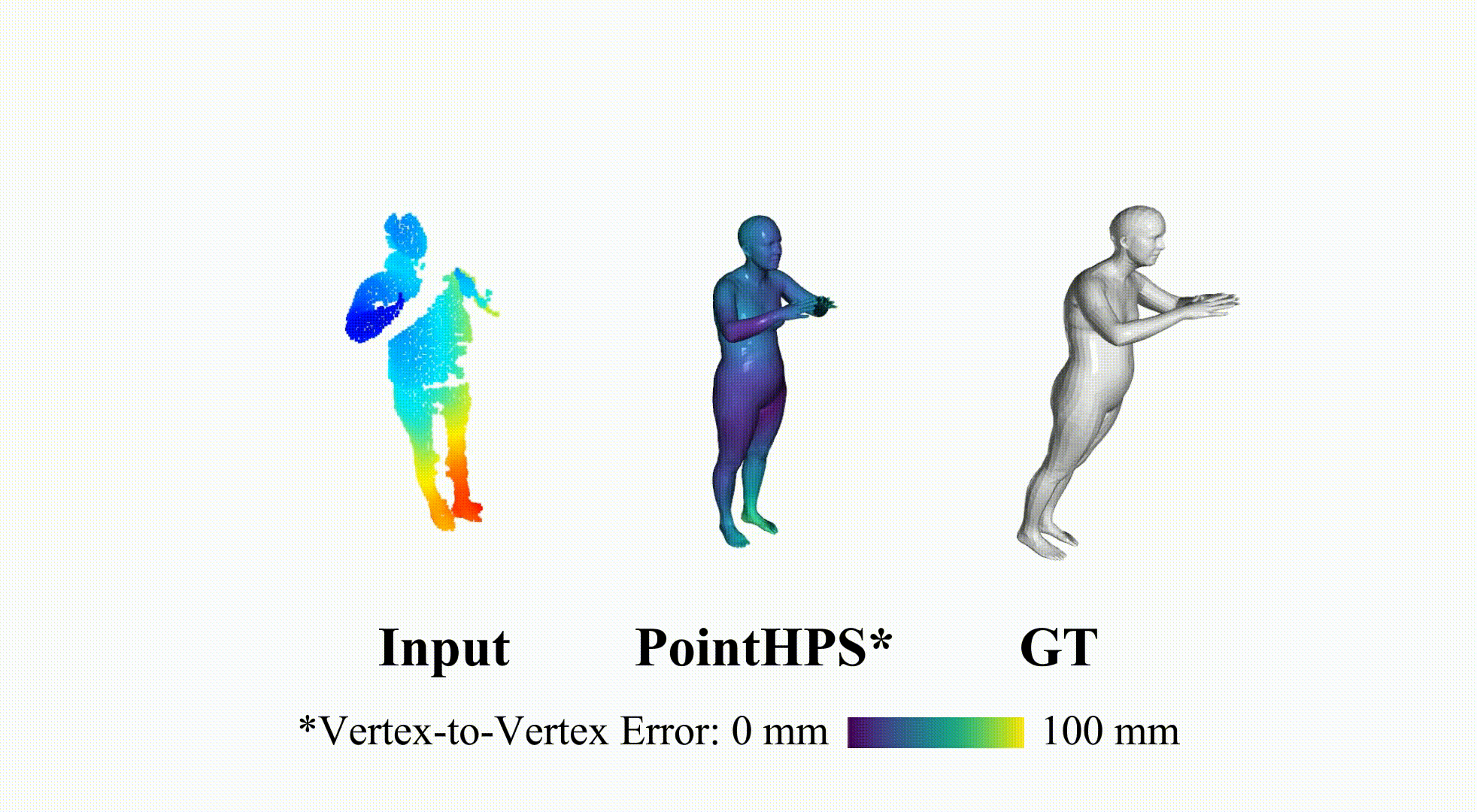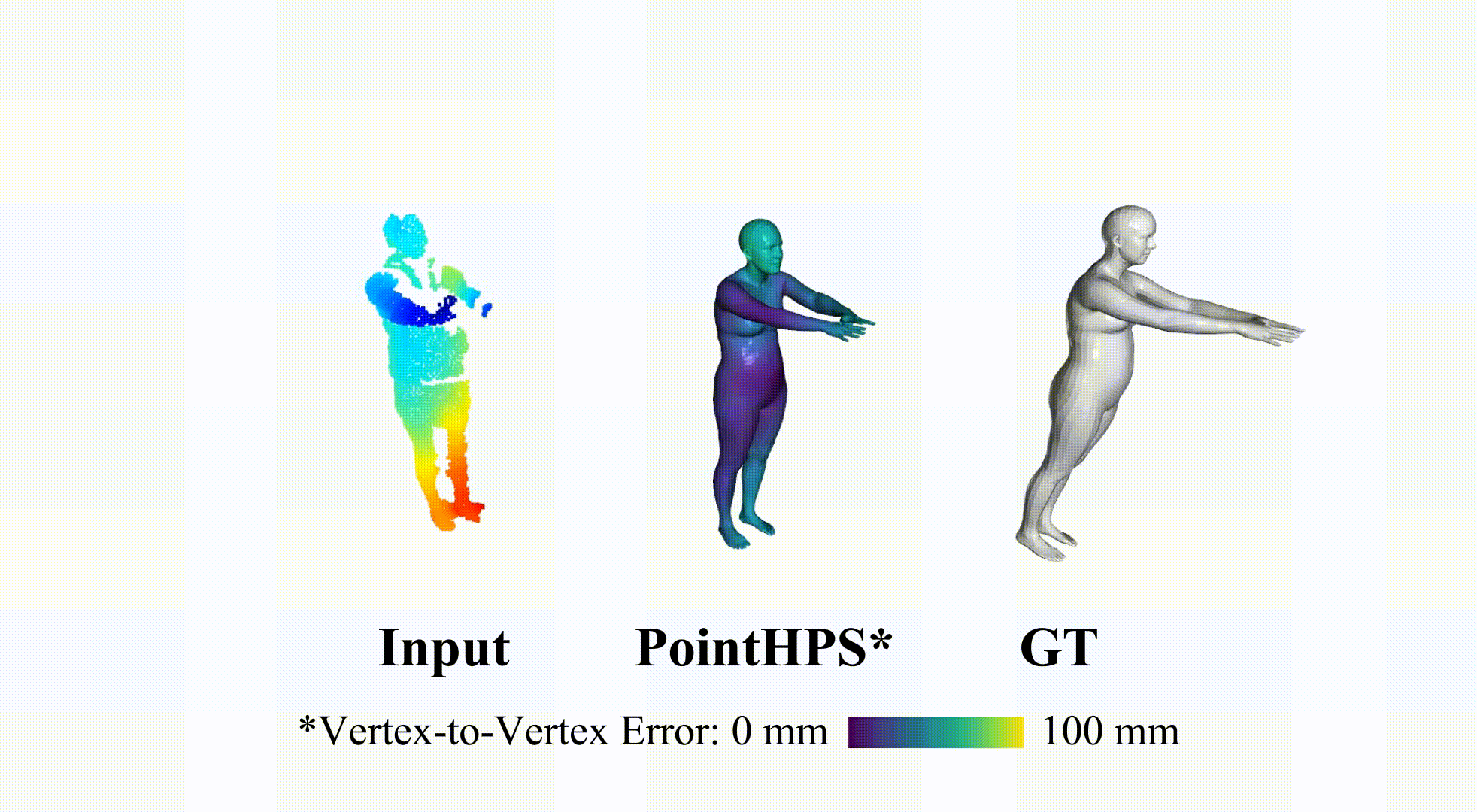
PointHPS: Cascaded 3D Human Pose and Shape Estimation from Point Clouds
arXiv Preprint, 2023


SMPL reconstruction from real depth sensor, which are partial point cloud inputs.
3DTopia-XL: Scaling High-quality 3D Asset Generation via Primitive Diffusion
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 (Highlight)
3DTopia-XL scales high-quality 3D asset generation using Diffusion Transformer (DiT) built upon an expressive and efficient 3D representation, PrimX. The denoising process takes 5 seconds to generate a 3D PBR asset from text / image input which is ready for graphics pipeline to use.
GaussianAnything: Interactive Point Cloud Latent Diffusion for 3D Generation
International Conference on Learning Representations (ICLR), 2025
GaussianAnything generates high-quality and editable surfel Gaussians through a cascaded 3D diffusion pipeline, given single-view images or texts as the conditions.
DiffTF++: 3D-aware Diffusion Transformer for Large-Vocabulary 3D Generation
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
Extension of our ICLR 2024 paper DiffTF. Joint training of diffusion model and Triplane representation increases the generation quality.
3DTopia: Large Text-to-3D Generation Model with Hybrid Diffusion Priors
arXiv Preprint, 2024
Text-to-3D Generation within 5 Minutes! A two-stage design, utilizing both 3D difffusion prior and 2D priors.
LN3Diff: Scalable Latent Neural Fields Diffusion for Speedy 3D Generation
European Conference on Computer Vision (ECCV), 2024
LN3Diff creates high-quality 3D object mesh from text within 8 V100-SECONDS.
Large-Vocabulary 3D Diffusion Model with Transformer
International Conference on Learning Representations (ICLR), 2024
DiffTF achieves state-of-the-art large-vocabulary 3D object generation performance with 3D-aware transformers.
FashionEngine: Interactive Generation and Editing of 3D Clothed Humans
arXiv Preprint, 2024
FashionEngine is an interactive 3D human generation and editing system with multimodal control (e.g., texts, images, hand-drawing sketches).
StructLDM: Structured Latent Diffusion for 3D Human Generation
European Conference on Computer Vision (ECCV), 2024
StructLDM is a diffusion-based unconditional 3D human generative model learned from 2D images.
PrimDiffusion: Volumetric Primitives Diffusion for 3D Human Generation
Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023
PrimDiffusion performs the diffusion and denoising process on a set of primitives which compactly represent 3D humans.
DeformToon3D: Deformable 3D Toonification from Neural Radiance Fields
International Conference on Computer Vision (ICCV), 2023
We learn a style field that deforms real 3D faces to styleized 3D faces.
EVA3D: Compositional 3D Human Generation from 2D Image Collections
International Conference on Learning Representations (ICLR), 2023 (Spotlight)
EVA3D is a high-quality unconditional 3D human generative model that only requires 2D image collections for training.
AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
ACM Transactions on Graphics (SIGGRAPH), 2022
AvatarCLIP empowers layman users to customize a 3D avatar with the desired shape and texture, and drive the avatar with the described motions using solely natural languages.
HumanLiff: Layer-wise 3D Human Generation with Diffusion Model
International Journal of Computer Vision (IJCV), 2025
We generate 3D digital humans using 3D diffusion model in a controllable, layer-wise way.
4DNeX: Feed-Forward 4D Generative Modeling Made Easy
arXiv Preprint, 2025
4DNeX is a feed-forward framework for generating 4D scene representations from a single image by fine-tuning a video diffusion model. It produces high-quality dynamic point clouds and enables downstream tasks such as novel-view video synthesis with strong generalizability.
Compositional Generative Model of Unbounded 4D Cities
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025
CityDreamer4D is a framework for unbounded 4D city generation that decouples static and dynamic scenes, achieving superior realism, multi-view consistency, and diverse styles.
GaussianCity: Generative Gaussian Splatting for Unbounded 3D City Generation
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025
GaussianCity is a framework for efficient unbounded 3D city generation using 3D Gaussian Splatting.
CityDreamer: Compositional Generative Model of Unbounded 3D Cities
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Unbouned 3D cities generated from 2D image collections!
EgoLM: Multi-Modal Language Model of Egocentric Motions
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 (Oral)
EgoLM is a language model-based framework that tracks and understands egocentric motions from multi-modal inputs, i.e., egocentric videos and sparse motion sensors.
HMD2: Environment-aware Motion Generation from Single Egocentric Head-Mounted Device
International Conference on 3D Vision (3DV), 2025
We propose HMD2, the first system for the online generation of full-body self-motion using a single head-mounted device (e.g. Project Aria Glasses) equipped with an outward-facing camera in complex and diverse environments.
Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild
European Conference on Computer Vision (ECCV), 2024
A large-scale, diverse, richly annotated human motion dataset collected in the wild with multi-modal egocentric devices.
Large Motion Model for Unified Multi-Modal Motion Generation
European Conference on Computer Vision (ECCV), 2024
Large Motion Model (LMM) is a motion-centric, multi-modal framework that unifies mainstream motion generation tasks into a generalist model.
MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
The first diffusion-model-based text-driven motion generation framework with probabilistic mapping, realistic synthesis and multi-level manipulation ability.
ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model
International Conference on Computer Vision (ICCV), 2023
ReMoDiffuse is a diffusion-model-based motion generation framework that integrates a retrieval mechanism to refine the denoising process, which enhances the generalizability and diversity.
HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling
European Conference on Computer Vision (ECCV), 2022 (Oral)
A large-scale multi-modal (color images, point clouds, keypoints, SMPL parameters, and textured meshes) 4D human dataset with 1000 human subjects, 400k sequences and 60M frames.
AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars
ACM Transactions on Graphics (SIGGRAPH), 2022
AvatarCLIP empowers layman users to customize a 3D avatar with the desired shape and texture, and drive the avatar with the described motions using solely natural languages.
PointHPS: Cascaded 3D Human Pose and Shape Estimation from Point Clouds
arXiv Preprint, 2023
SMPL reconstruction from real depth sensor, which are partial point cloud inputs.
STream3R: Scalable Sequential 3D Reconstruction with Causal Transformer
arXiv Preprint, 2025
STream3R reformulates dense 3D reconstruction into a sequential registration task with causal attention.
MEAT: Multiview Diffusion Model for Human Generation on Megapixels with Mesh Attention
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025
With mesh attention designed for efficient cross-view feature fusion, MEAT is the first human multiview diffusion model that can generate dense, view-consistent multiview images at a resolution of 1024x1024.
GeneMAN: Generalizable Single-Image 3D Human Reconstruction from Multi-Source Human Data
arXiv Preprint, 2024
GeneMAN is a generalizable framework for single-view-to-3D human reconstruction, built on a collection of multi-source human data.
SurMo: Surface-based 4D Motion Modeling for Dynamic Human Rendering
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Dynamic human rendering with the joint modeling of motion dynamics and appearance.
SHERF: Generalizable Human NeRF from a Single Image
International Conference on Computer Vision (ICCV), 2023
Reconstruct human NeRF from a single image in one forward pass!
Garment4D: Garment Reconstruction from Point Cloud Sequences
35th Conference on Neural Information Processing Systems (NeurIPS), 2021
The first attempt at separable and interpretable garment reconstruction from point cloud sequences, especially challenging loose garments.
EgoLM: Multi-Modal Language Model of Egocentric Motions
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 (Oral)
EgoLM is a language model-based framework that tracks and understands egocentric motions from multi-modal inputs, i.e., egocentric videos and sparse motion sensors.
Unified 3D and 4D Panoptic Segmentation via Dynamic Shifting Networks
Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2023
Extension of the CVPR21 Version; Extend DS-Net to 4D panoptic LiDAR segmentation by the temporally unified instance clustering on aligned LiDAR frames.
4D Panoptic Scene Graph Generation
Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS), 2023 (Spotlight)
To allow artificial intelligence to develop a comprehensive understanding of a 4D world, we introduce 4D Panoptic Scene Graph (PSG-4D), a new representation that bridges the raw visual data perceived in a dynamic 4D world and high-level visual understanding.
Versatile Multi-Modal Pre-Training for Human-Centric Perception
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 (Oral)
The first to leverage the multi-modal nature of human data (e.g. RGB, depth, 2D key-points) for effective human-centric representation learning.
LiDAR-based Panoptic Segmentation via Dynamic Shifting Network
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Rank 1st in the public leaderboard of SemanticKITTI panoptic segmentation (2020-11-16); A learnable clustering module is designed to adapt kernel functions to complex point distributions.
Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR-based Perception
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2021
Journal Extension of the CVPR21 version; Extend the cylindrical convolution to more general LiDAR-based perception tasks.
Cylindrical and Asymmetrical 3D Convolution Networks for LiDAR Segmentation
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021 (Oral)
Rank 1st in the public leaderboard of SemanticKITTI semantic segmentation (2020-11-16); Cylindrical 3D convolution is designed to explore the 3D geometric pattern of LiDAR point clouds.
LRC-Net: Learning Discriminative Features on Point Clouds by Encoding Local Region Contexts
Computer Aided Geometric Design, 2020, 79: 101859. (SCI, 2017 Impact factor: 1.421, CCF B)
To learn discriminative features on point clouds by encoding the fine-grained contexts inside and among local regions simultaneously.
EgoTwin: Dreaming Body and View in First Person
arXiv Preprint, 2025
We propose EgoTwin, a diffusion-based framework that jointly generates egocentric video and human motion in a viewpoint consistent and causally coherent manner. Generated videos can be lifted into 3D scenes using camera poses derived from human motion via 3D Gaussian Splatting.
EgoLM: Multi-Modal Language Model of Egocentric Motions
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025 (Oral)
EgoLM is a language model-based framework that tracks and understands egocentric motions from multi-modal inputs, i.e., egocentric videos and sparse motion sensors.
EgoLife: Towards Egocentric Life Assistant
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025
We introduce EgoLife, a project to develop an egocentric life assistant that accompanies and enhances personal efficiency through AI-powered wearable glasses.
HMD2: Environment-aware Motion Generation from Single Egocentric Head-Mounted Device
International Conference on 3D Vision (3DV), 2025
We propose HMD2, the first system for the online generation of full-body self-motion using a single head-mounted device (e.g. Project Aria Glasses) equipped with an outward-facing camera in complex and diverse environments.
Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild
European Conference on Computer Vision (ECCV), 2024
A large-scale, diverse, richly annotated human motion dataset collected in the wild with multi-modal egocentric devices.
CVPR 2025 Doctoral Consortium
China3DV Rising Star Award
NTU Research Scholarship
ICBC Scholarship (Top 3%)
Hua Wei Scholarship (Top 1%)
Tung OOCL Scholarship (Top 5%)
Egocentric 3D Capture and Understanding
From High-Fidelity 3D Generative Models to Dynamic Embodied Learning
Associate Editor: IROS’25
Conference Reviewer: CVPR’21/23/24/25, ICCV’23/25, ECCV’24, NeurIPS’22/23/24/25, ICML’23/24, ICLR’24/25/26, SIGGRAPH’23/24/25, SIGGRAPH Asia’23/24/25, AAAI’21/23, 3DV’25, IROS’25
Journal Reviewer: TPAMI, IJCV, TVCG, TCSVT, JABES, PR, CVIU, TOG
Workshop / Tutorial / Challenge Organizer: From Video Generation to World Model@CVPR’25, OmniObject3D Challenge@ICCV’23
Guest Lecture on 3D Generative Models @ UMich EECS 542.
NTU CE/CZ1115 Introduction to Data Science and Artificial Intelligence (Teaching Assistant)
NTU CE2003 Digital System Design (Teaching Assistant)
NTU CE/CZ1115 Introduction to Data Science and Artificial Intelligence (Teaching Assistant)
NTU SC1013 Physics for Computing (Teaching Assistant)
A collection of my human-related work, including HCMoCo, Garment4D, AvatarCLIP, EVA3D, EgoLM.