EgoLM: Multi-Modal Language Model of Egocentric Motions
- Fangzhou Hong1,2
- Vladimir Guzov1,3
- Hyo Jin Kim1
- Yuting Ye1
- Richard Newcombe1
- Ziwei Liu2✉
- Lingni Ma1✉
- 1Meta Reality Labs Research
- 2S-Lab, Nanyang Technological University
- 3University of Tuebingen
EgoLM is a language model-based framework that tracks and understands egocentric motions
from multi-modal inputs, i.e., egocentric videos and sparse motion sensors.
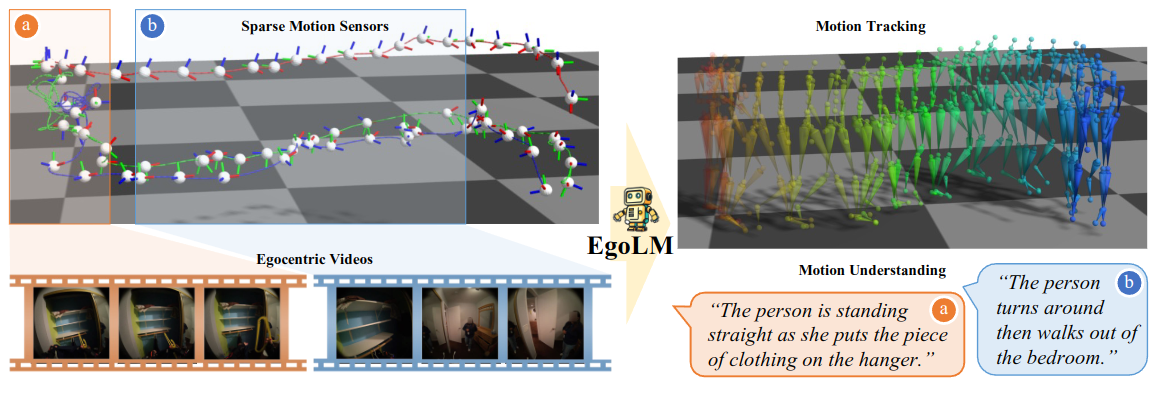


Upper right: Our motion tracking results; Lower middle: Our motion understanding results.
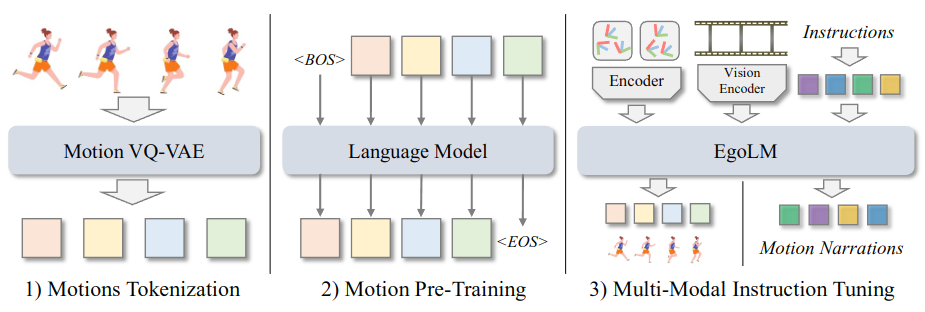 Figure 1. Overview of EgoLM.
Figure 1. Overview of EgoLM.
Three steps are designed for the training of EgoLM. In the first step, we train a motion VQ-VAE as the motion tokenizer. The second step is motion pre-training for motion distribution learning. The last step is multi-modal instruction tuning to guide the model to perform motion tracking and understanding.
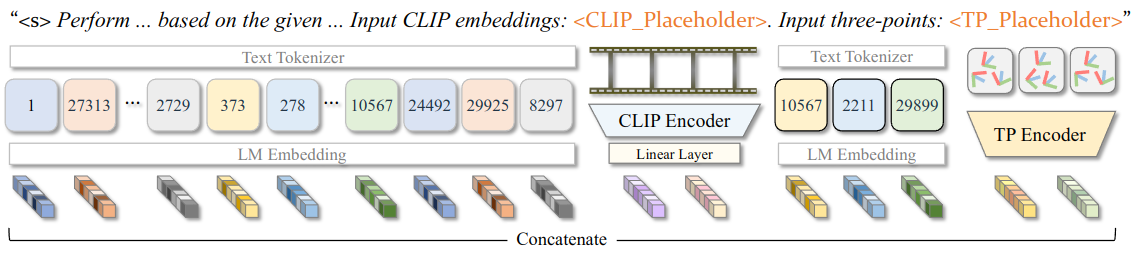 Figure 2. Details of Multi-Modal Instruction Tuning.
Figure 2. Details of Multi-Modal Instruction Tuning.
Different modalities, e.g., egocentric videos and sparse motion sensors, are encoded and projected to the language model space. Their features are concatenated in the order of the instruction template, and input into the transformer layers of the language model.
@article{EgoLM,
title={EgoLM: Multi-Modal Language Model of Egocentric Motions},
author={Fangzhou Hong and Vladimir Guzov and Hyo Jin Kim and Yuting Ye and Richard Newcombe and Ziwei Liu and Lingni Ma},
journal={arXiv preprint arXiv:2409.18127},
year={2024}
}
Project Aria: we use the project Aria glasses in our research to capture egocentric videos.
Nymeria Dataset: a large-scale, diverse, richly annotated human motion dataset collected in the wild with multi-modal egocentric devices.