Versatile Multi-Modal Pre-Training for
Human-Centric Perception
- Fangzhou Hong1
- Liang Pan1
- Zhongang Cai1,2,3
- Ziwei Liu1✉
- 1S-Lab, Nanyang Technological University
- 2SenseTime Research
- 3Shanghai AI Laboratory
CVPR 2022 (Oral)
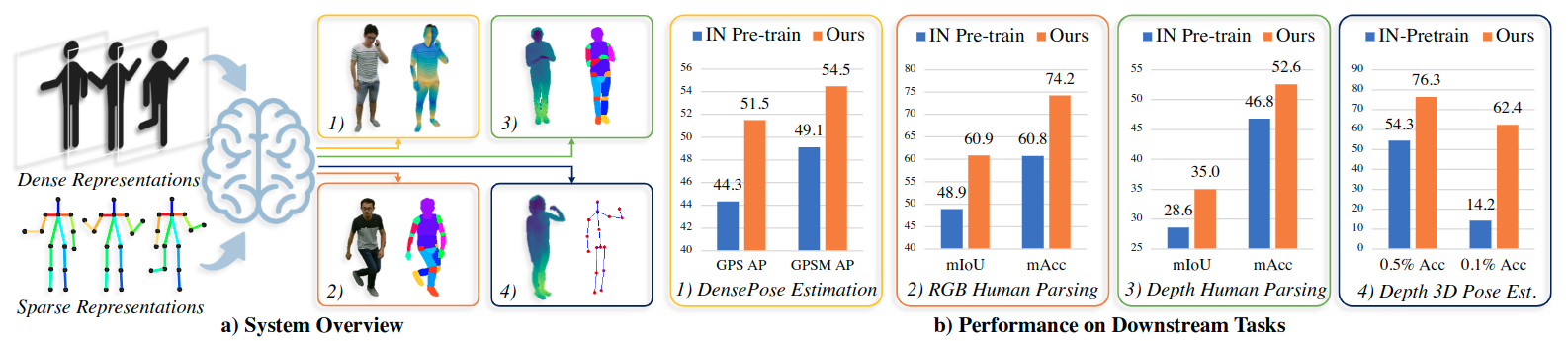
Figure 1. An Overview of HCMoCo. a) We present HCMoCo, a versatile multi-modal pre-training framework that takes multi-modal observations of human body as input for human-centric perception. The pre-train models can be transferred to various human-centric downstream tasks with different modalities. b) Our HCMoCo shows superior performance on all four downstream tasks, especially for data-efficient settings (10% DensePose, 20% RGB/depth human parsing, 0.5/0.1% 3D pose estimation). 'IN' stands for ImageNet.
Abstract
Human-centric perception plays a vital role in vision and graphics, but their data annotations are usually prohibitively expensive.
Therefore, it is desirable to have a versatile pre-train model that serves as a foundation for data-efficient downstream task transfer.
To this end, we propose the Human-Centric Multi-Modal Contrastive Learning framework HCMoCo that leverages the multi-modal nature of human data (e.g. RGB, depth, 2D keypoints) for effective representation learning.
The objective comes with two main challenges: dense pre-train for multi-modality data and efficient usage of sparse human priors.
To tackle the challenges, we design the novel Dense Intra-sample Contrastive Learning and Sparse Structure-aware Contrastive Learning targets by hierarchically learning a modal-invariant latent space featured with continuous and ordinal feature distribution and structure-aware semantic consistency.
HCMoCo can provide pre-train for different modalities by combining heterogeneous datasets, which allows efficient usage of existing task-specific human data.
Extensive experiments on four different downstream tasks of different modalities demonstrate the effectiveness of HCMoCo, especially under data-efficient settings (7.16% and 12% improvement on DensePose Estimation and Human Parsing).
Moreover, we also demonstrate the versatility of HCMoCo by exploring cross-modality supervision and missing-modality inference, validating its strong ability in cross-modal association and reasoning.
Links



HighLights
(a) General Paradigm of HCMoCo
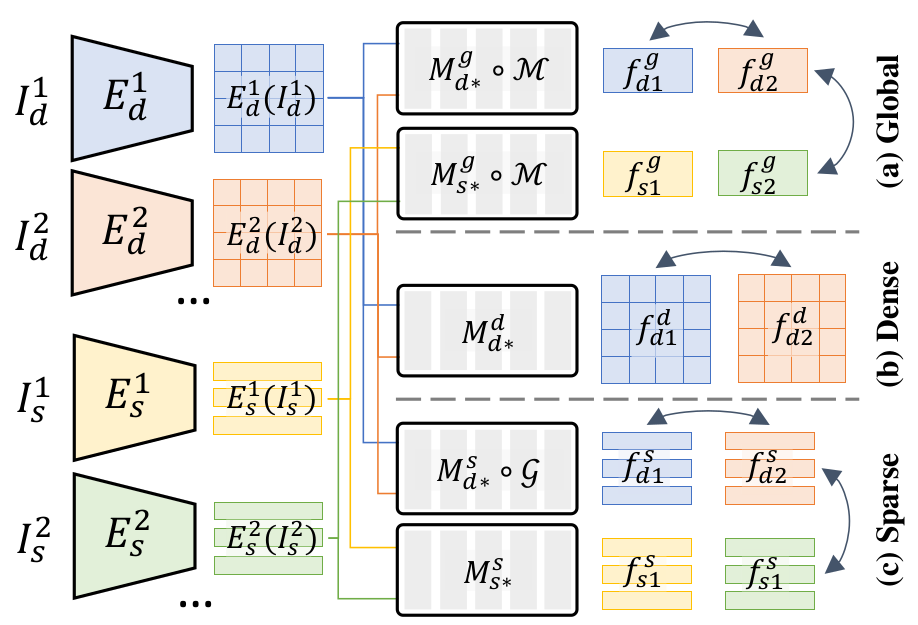 Figure 2. Illustration of the general paradigm of HCMoCo.
Figure 2. Illustration of the general paradigm of HCMoCo.
We group modalities of human data into dense I∗d and sparse rep-
resentations I∗s.
Three levels of embeddings (i.e. global, dense and sparse embeddings) are extracted.
Combining the nature of human data and tasks, we present contrastive learning targets for each level of embedding.
Specifically, we present a) Sample-level Modality-invariant Representation Learning; b) Dense Intra-sample Contrastive Learning;
c) Sparse Structure-aware Contrastive Learning, respectively.
(b) Versatility of HCMoCo
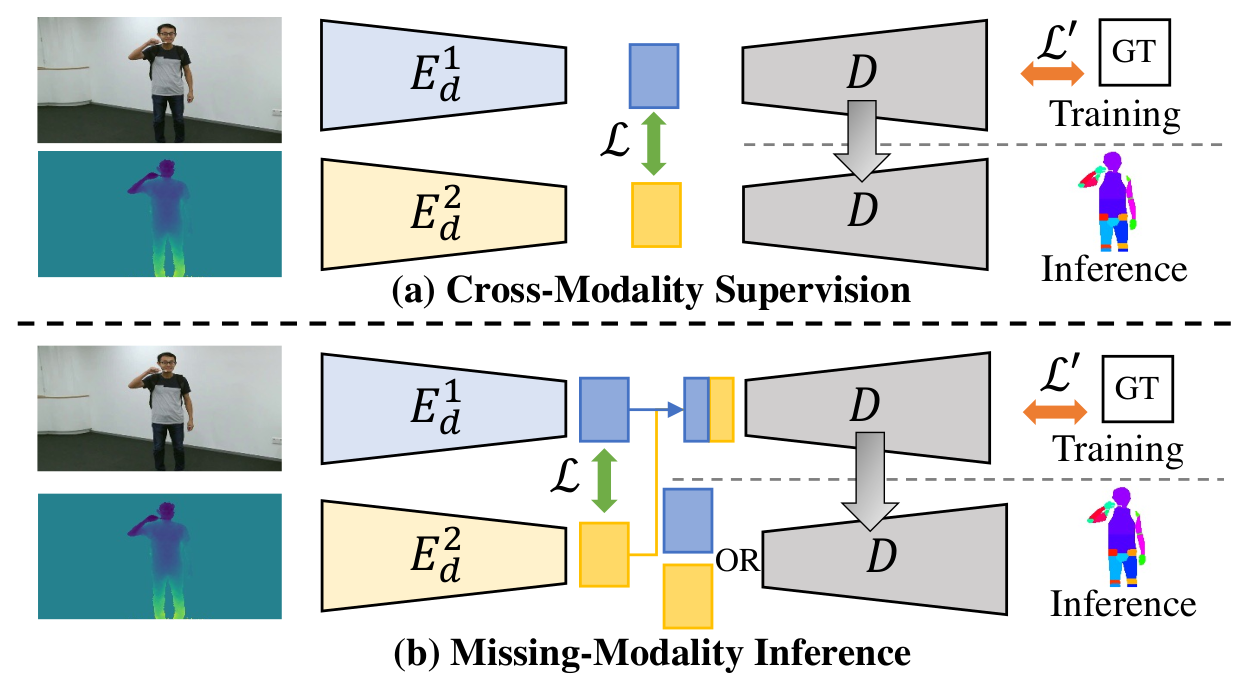 Figure 3. Pipelines of Two Applications of HCMoCo.
Figure 3. Pipelines of Two Applications of HCMoCo.
On top of the pre-train framework HCMoCo, we propose to further extend it on two direct applications:
Cross-Modality Supervision and Missing-Modality Inference. The
extensions are based on the key design of HCMoCo: dense
intra-sample contrastive learning target. With the feature
maps of different modalities aligned, it is straightforward to
implement the two extensions.
(c) NTURGBD-Parsing-4K Dataset
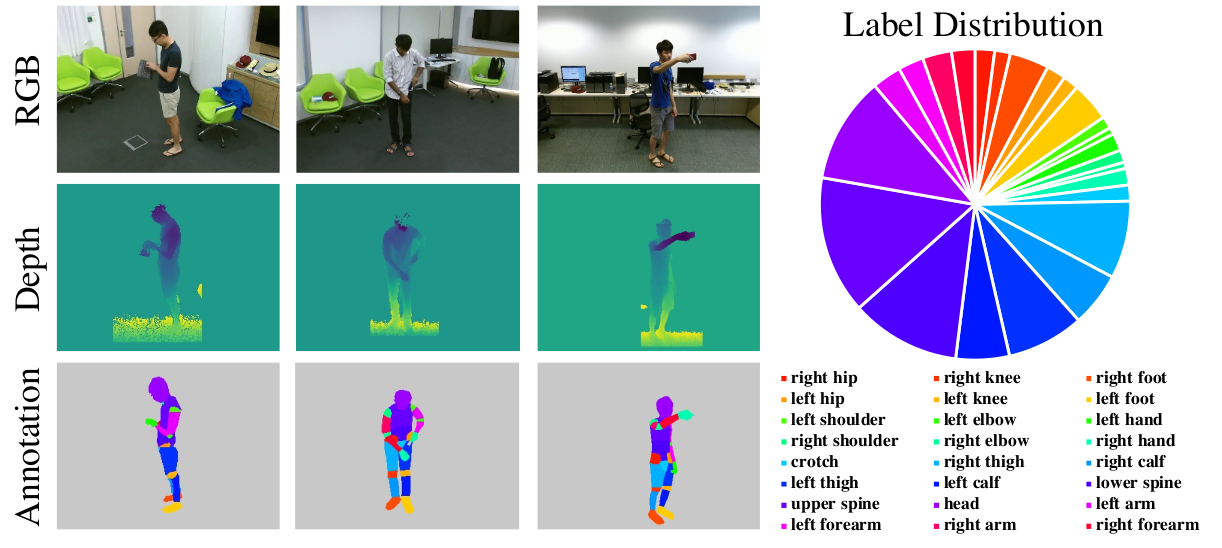 Figure 4. Illustration of the RGB-D human parsing dataset NTURGBD-Parsing-4K.
Figure 4. Illustration of the RGB-D human parsing dataset NTURGBD-Parsing-4K.
We contribute the first RGB-D human parsing
dataset: NTURGBD-Parsing-4K. The RGB and depth are
uniformly sampled from NTU RGB+D (60/120).
We annotate 24 human parts for paired
RGB-D data.
The train and test set both have 1963 samples. The whole
dataset contains 3926 samples. Hopefully, by contributing
this dataset, we could promote the development of both hu-
man perception and multi-modality learning.
Downloads are available here.
Bibtex
@article{hong2022hcmoco,
title={Versatile Multi-Modal Pre-Training for Human-Centric Perception},
author={Hong, Fangzhou and Pan, Liang and Cai, Zhongang and Liu, Ziwei},
journal={arXiv preprint arXiv:2203.13815},
year={2022}
}